捉虫者日记I - 和自己Race的单线程应用
因为工作原因实在很久没写过博客了,但终于下决心不能放弃这个习惯。无奈时隔几个月手生的紧,故决定先选一些小话题写写短文权当练手。《捉虫者日记》将会是一系列短博客,简单记录下工作中我碰见过有趣或印象深刻的Debug经历,一方面作为给我自己的备忘录,另一方面也希望能起抛砖引玉的作用。
问题背景:未知的Race线程
众所周知,我从事分布存储相关工作。具体业务中,客户端创建文件的流程如下(为简化阅读,已隐去大部分具体细节并简化了系统结构):
- 给定文件名
{fileName},将同名文件重命名为/overwrite/{UUID}/{fileName} - 创建空文件
{fileName},该操作在存在同名文件的情况下会失败
上述一切操作均需要通过发送RPC给远程元数据服务器MetaServer完成,且在服务器内部所有操作均拥有原子性(Atomicity)。RPC接口定义如下:
// Rename srcFile record to dstFile, iff srcFile exists while dstFile doesn't.
// Return true if renaming actually happens; Return false otherwise.
bool renameFileEntry(const string& srcFile, const string& dstFile);
// Create srcFile record, iff srcFile doesn't exist.
// Return true if creation actually happens; Return false otherwise.
bool createFileEntry(const string& srcFile);
而创建文件的客户端业务实现则非常直观:
bool Client::createFile(const string& fileName) {
auto metaServer = getMetaServer();
metaServer->renameFileEntry(
fileName, sformat("/overwrite/{}/{}", makeUUID(), fileName));
return metaServer->createFileEntry(fileName);
}
其中,我刻意忽略了 renameFileEntry的返回值。因为无论其成功与否都可以安全地创建文件,哪怕MetaServer出问题导致 srcFile存在但没被成功重命名,客户端 createFileEntry也只是返回失败而已——调用者完全可以通过重试来完成操作。
实际运行中,我发现上述流程有几亿分之一的概率出现意想不到的情况:尽管 createFile返回值显示文件创建成功,最终却只发现了 /overwrite/UUID/filename的文件记录。起初,这并没有让我太惊讶,两个客户端对同名文件Race能够轻易造成上述异常结果:
假如有两个 createFile客户端同时/先后执行,且后一个客户端在最后一步创建文件时因为任何原因失败(如网络错误,MetaServer崩溃等),从CreateFile1的视角看都符合上述“函数返回成功,但文件记录不存在”的异常情况。
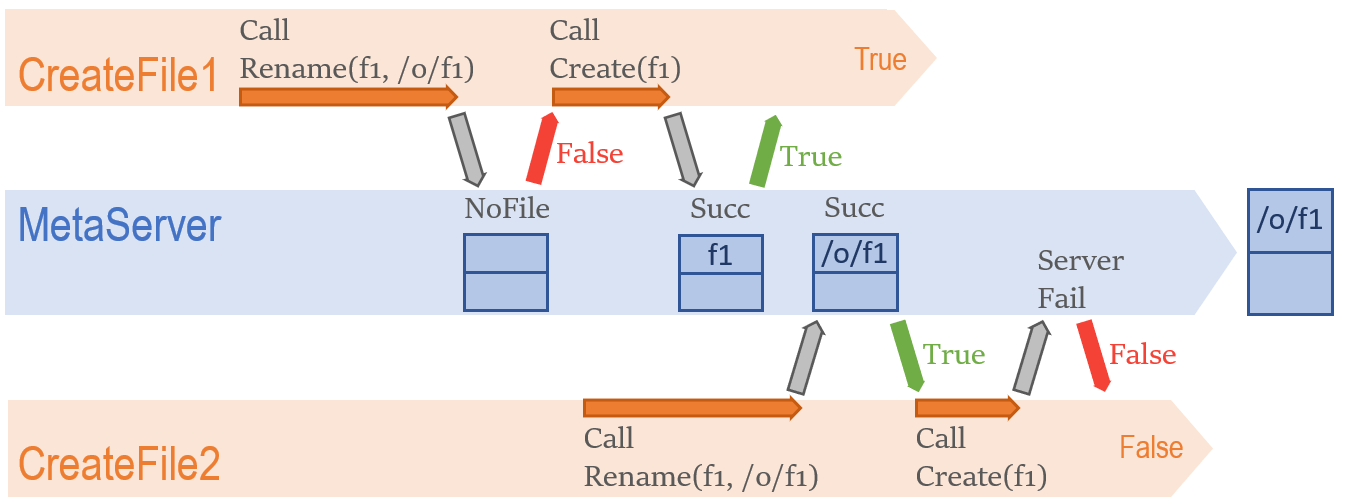
然而当我调查客户端调用记录后,诡异的事情发生了——多种证据显示,对该文件名,CreateFile有且仅有一次调用。换句话说, createFile作为一个单线程函数,竟然和自己Race了??为搞清楚问题发生的细节,我进行了多番取证。但不幸的是,因为问题曝光时间过晚,相关日志已全部丢失,现在唯一的线索就是上文提到的源码。
调查陷入僵局,看起来如此单纯的问题空间(一个单线程同步业务路逻辑 + 一个全原子化操作的MetaServer)竟产生了Race Condition并导致完全出乎意料的结果。经过一段时间和客户端代码大眼瞪小眼,一个推论渐渐形成。
推论:乱序的MetaServer操作
前文的Debug过程中,我之所以先入为主地将异常归因为执行两个文件名相同的 createFile函数,是因为假定了对于该函数,其内部实现一定是有序的。换句话说, renameFileEntry应该发生在 createFileEntry之前。如果放弃这个假设,我能轻易找到单 createFile客户端造成异常结果的例子:
-
createFileEntry创建该文件记录并返回成功 -
renameFileEntry将刚创建好的记录重命名成为/overwrite/...
那么MetaServer操作乱序有可能么?当然有:
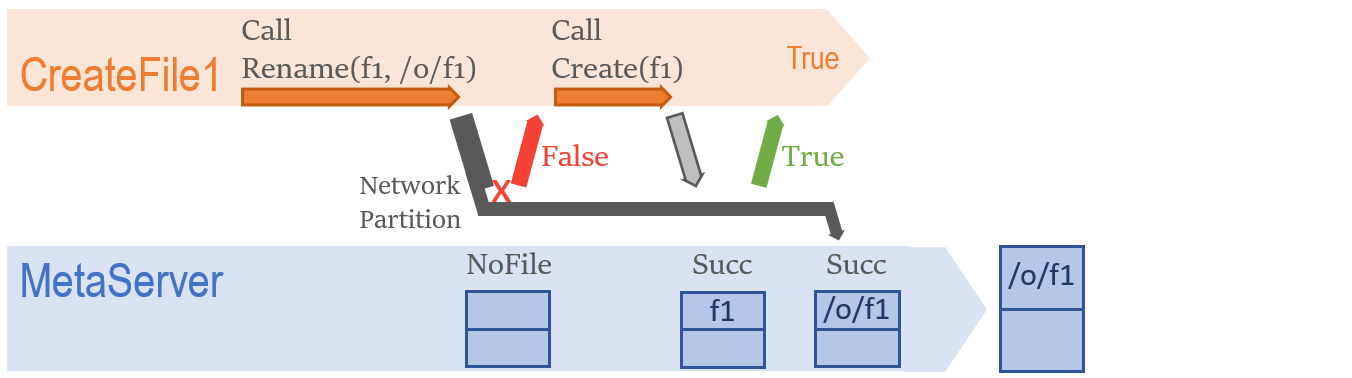
一个简单的例子是Network Partition。由于从客户端业务函数向MetaServer的通讯通过RPC实现,当网络出现问题时 renameFileEntry请求可能以意想不到的方式失败:该请求实际已经到达服务器,但因为一些原因客户端并不知情并马上返回网络错误。在这之后,失去客户端追踪的 renameFileEntry请求成为一个引爆时间未知的炸弹,可能在任何时候被MetaServer处理。假如这个时间点处于 createFileEntry发生后,将不难想象地造成上述异常。
如前文所述,由于相关日志已经年久丢失,我们无从验证该推论正确性,假如我们能看到日志,我们应该能找到一条客户端认为 metaServer->renameFileEntry因为网络问题而失败的logline。经过守株待兔,我们成功在该异常再一次复现时从日志中找到了需要的证据。
总结反思
起初我对该Bug的成因百思不得其解,并花费相当多人力物力试图证明有两个客户端对同一文件先后执行,其根本谬误在于被该函数的顺序实现、MetaServer操作的原子性所蒙骗,认为单一工作流程不可能造成任何Race。事实上,忽略RPC用到的通讯协议及框架让我忽视了该过程多线程的本质。
另一个反思在于,对RPC,我们可以认为其返回成功时已执行成功,但不能假设其返回失败时一定执行失败。
#eof